Have you accidentally (or purposefully) deleted the inheritance of your auditing entries on an NTFS folder and want them back? Have you been playing with SetAuditRuleProtection and scratching your head as to why it doesn’t appear to work? Well, I was too, and then I stumbled upon this Stack Overflow article.
Turns out we only had an Audit SACL at the root that we wanted to have inherited everywhere. That means the ones that weren’t inheriting properly didn’t have any Audit SACL on them, and therefore SetAuditRuleProtection didn’t do anything.
As per the article we did the following (aka, add a temp rule while setting SetAuditRuleProtection, and then removing the temp rule). Make sure you are running Get-Acl with the -Audit parameter. This is how we ended up blowing away all the inheritance – when you don’t specify -Audit Audit SACL info isn’t grabbed, so it appears empty in the object and when applied…overwrites it to NULL!
On my current project we are using DataSync to move data from an S3 bucket to an FSx ONTAP device via NFS. The transferred data is subsequently consumed and modified by another process that needs to have permissions to that data.
Unfortunately, by default, AWS DataSync sets the default POSIX permissions to 755 with an owner UID:GID of 65534:65534 (aka anonymous) when transferring from S3 to NFS. This was preventing our subsequent process from modifying and moving files to subsequent locations on the FSx ONTAP device.
However, on that same user guide page further up, AWS DataSync data that is copied from NFS to S3 maintains the original permissions as S3metadata. The metadata is used with AWS Storage Gateway or if you DataSync the data back to an NFS share. Based on this information, I was confident that we could set said metadata on our S3 objects and have them land with the correct permissions. Sadly, it does not tell you what that metadata looks like.
Well friends, I’m here to help!
First, I found this AWS blog article about how you can setup DataSync to replicate your NFS server to an S3 bucket. In the article, there’s a picture of a file’s metadata!
Lo-and-behold, adding the following metadata block to an object via put-object or copy-object, allowed for the file to land on the FSx ONTAP server with the correct UID, GID, and permission set.
This worked well and good for the files. However, the root folder the DataSync destination was attached to on the FSx ONTAP kept getting it’s permissions overwritten with the default permissions – 755 with an owner UID:GID of 65534:65534. “Folders” don’t really exist in S3, they are a manifestation of the key’s name when it includes a “/”.
Searching didn’t save us, and we had to stand up a quick NFS to S3 environment. We transferred some files with various permissions and looked at what ended up in the S3 bucket. Sadly, it looked the same from the AWS portal – a “folder” with some files in it, with no ability look at a folder’s metadata.
DataSync is creating an actual “folder object” that has the metadata attached to it (e.g. “folderName/”)!
Using that understanding, in our source S3 bucket we created the correct “folder object” with the right metadata attached to it. The “folder object” is set as the the DataSync source folder. And now when the DataSync task runs, the correct permissions are set on the subsequent root destination folder!
My typically rock-solid home internet connection went down a few days ago. No fault of the ISP, but we had a fiber “cut” – more like snap, as I think the overhead cable got caught on a passing truck, shooting it half a block. Sadly, the earliest time they could get a service tech out to string some new fiber was as week later.
My GoogleFi tethering worked great for a few days with my work machine to get me through the wee, but it really wasn’t a great solution for anyone other than me. Also, at 25GB without any great way to add more, I started looking for other solutions (turns out video calls burn through the GBs).
The first thing that came to mind was something like getting T-mobile home internet for a month, or some sort of hotspot. That would definitely be a short term solution and not something I’d keep running all the time. Ick to more monthly fees for something I’ve needed less than 5 times in as many years. What I really needed was a preloaded block of data on a SIM card – something that seems to be easily found in the EU, but not so easily found in the US.
And then I stumbled upon IOT sim cards – thanks Amazon. While not perfect, as the data does expire, these are a great way to only really pay for what you need in that time frame.
Remove the battery & plug it into the UPS (apparently more power when not on battery)
Factory reset it
Check for updates
Enable the ethernet port (if not already)
Enable IP Passthrough
I did not change the APN to what EIOTCLUB says to (americas.bics) as that downgraded me to 4G whereas the default after the factory reset gave me sweet, sweet 5Gs.
Then in pfsense I did the following (thanks Josh):
Created and enabled a new Interface Assignment named “WAN_LTE” that uses DHCP on IPv4 and blocks reserved networks (both)
Created a new Gateway tied to that interface, but using 8.8.8.8 as the Monitor IP (default doesn’t work)
Updated the monitoring intervals to be closer to what Josh has (30 seconds
Created a new Gateway Group that included both my fiber (Tier 1) and this new LTE gateway (Tier 5)
Set the default gateway to be the new Gateway Group
And tada! I’m back on the internet throughout my house (outbound only).
With EIOTCLUB’s mobile app, it was super easy to view the current usage and buy a larger block of data. Once this block and outage has expired, I’ll probably get a 1GB for 360 days ($9 as of this writing). That way it can continue to monitor the connection throughout the year, and if something does go down, while manual, it’s very easy to reload the SIM and get back online.
With the recent-ish announcement of Bitwarden being able to store SSH keys, I’ve been playing around to get it to work in my WSL2 Ubuntu host. While I normally use a windows machine, I do a lot in WSL2 for dev & ops.
Configure and enable the the windows ssh-agent functionality as per the Bitwarden instructions. Once that is complete, you will be able to access keys stored in Bitwarden from Powershell via
ssh-add -L
In powershell, install npiperelay (I used chocolatey, but you can use whatever, just get where the exe is installed so you can modify the script later)
choco install npiperelay
In WSL2, install socat
sudo apt install socat
In WSL2 create a script that will rebind the ssh-agent. I save this as ~/scripts/agent-bridge.sh.
export SSH_AUTH_SOCK=$HOME/.ssh/agent.sock
ss -a | grep -q $SSH_AUTH_SOCK
if [ $? -ne 0 ]; then
rm -f $SSH_AUTH_SOCK
( setsid socat UNIX-LISTEN:$SSH_AUTH_SOCK,fork EXEC:"/mnt/c/ProgramData/chocolatey/lib/npiperelay/tools/npiperelay.exe -ei -s //./pipe/openssh-ssh-agent",nofork & ) >/dev/null 2>&1
fi
Make the script executable
chmod +x ~/scripts/agent-bridge.sh
Edit your ~/.bashrc and add the following line at the end
source ~/scripts/agent-bridge.sh
Restart your shell and then you should be able to list your current keys with ssh-add -l!
I’m just outlining my tweaks to my MS-01s BIOS for future posterity. This is based on the 1.26 BIOS that was released in October (see previous article about updates).
As a note, I’m using these as my K3s cluster nodes and so don’t need some of the onboard items that I’m disabling. Also, only modifications to default are listed below.
Main
Update System Date and Time if required
Advanced
Onboard Devices settings
VMD setup menu
Enable VMD controller: Disabled (not using RAID)
HD Audio: Disabled
SA-PCIE PORT
PCIE4.0x4 SSD ASPM: Disabled
PCH-PCIE PORT
I226-V NIC ASPM: Disabled*
I226-LM ASPM: Disabled*
WIFI: Disabled
WIFI ASPM: Disabled
*I am disabling ASPM on the NICs due to a lot of wonky networking items. Based on a reddit thread, this definitely fixed it.
Man, this blog seems to be all my trials and tribulations with kubernetes at this point. Well, to add to it, here’s another issue I stumbled into…
Tl;dr – when using metallb with kube-vip do not use the --services switch for generating the daemonset manifest, as that will conflict with metallb for load-balancing your services.
I built a new cluster (based on Miniforum’s awesome MS-01) about two months ago. As part of this new build, I wanted to load balance the control plane instead of the DNS round-robin I had been using. This lead me to kube-vip.
(Un)Fortunately, kube-vip can also provide the same capabilities as metallb – in that it can provide load balancing capabilities to services running in the cluster on bare metal without an external load balancer. However, I was happy with metallb in the old cluster and didn’t want to change that part.
So I went and installed k3s with the created manifest per the kube-vip k3s instructions which links to their manifest creation instructions. I even went and looked at other, similar articles to see basically the same instructions.
All was pretty good until I started having some weird issues where my ingresses would just sort of go offline. When I’d try to hit a website (like this one), I’d never see the request make it to the ingress, but I could ping the IP. Not seeing the request in the ingress logs made me think it was something with metallb not doing it’s L2 advertisement correctly. This seemed to happen if and when I had to restart the nodes for any reason (patches usually).
Knowing the only real difference for this piece was related to kube-vip, I knew something was going on between kube-vip and metallb. I just didn’t know what. I attempted to upgrade kube-vip, and downgrade metallb, but nothing seemed to work. Figuring it was kube-vip and metallb fighting, I disabled kube-vip from the services (even though I didn’t want it touching them in the first place). Thinking I had fixed it, I left it. Not more than 3 hours later, the ingresses went down again. In fact, I actually made it worse where every 2-4 hours the ingresses would go do for 20 minutes, but then fix themselves. It was incredibly nerve wracking.
Metallb even has a whole troubleshooting section on it’s website for this exact issue. Sadly, nothing there really helped, but there were some weird pieces, like with arping where it’d return multiple MAC addressess for the initial ping until it standardized on the right one. And then yesterday, while the ingresses went down I, on a whim, cleared the arp cache on my router to have it immediately fix the problem. Hmmm, could it be something with the router?!
In a fit of frustration, I deleted the kube-vip daemonset from the cluster. Surely, that would fix it?! No, 2 hours later it was flapping again!
Thinking through the router issue, the only thing I could think of was that it was getting conflicting info, and the only way that would happen is if there were duplicate IPs on the network. I logged into each one of the servers and ran ip -o -f inet addr show. Lo and behold on two different servers I saw the same IP address. Metallb doesn’t bind the IP to the network address, kube-vip does, so it was kube-vip that was causing the issues! Good thing I deleted it, but now I needed to restart the servers to have it remove the IP binding. Thankfully after the restart the IPs were removed.
However, I really liked the fact that my control plane is load balanced instead of pointing to an individual node or relying on round-robin for DNS. Digging into the configuration a bit more, I see that there are 2 main features: --controlplane and --services. Sadly, the default instructions include services, which is what metallb was doing for me. Therefore, I updated the manifest script to be the following:
I’ve had an issue for quite awhile with a handful of my pods on k3s – when they get recreated they sit in “ContainerCreating” after it’s been properly assigned to a node, for upwards of 10-15mins. After which it starts normally and continues on it’s way.
Well, I finally found what the issue was after digging into the logs via journalctl -u k3s as this was happening on my new server all the sudden too!
Oct 02 13:02:10 mini01 k3s[1128132]: W1002 13:02:10.887356 1128132 volume_linux.go:49] Setting volume ownership for /var/lib/kubelet/pods/7ce5e4e3-8688-4b72-96f0-c1ff95508fa1/volumes/kubernetes.io~csi/pvc-0305f670-29a9-4be1-9b69-f9213369dde8/mount and fsGroup set. If the volume has a lot of files then setting volume ownership could be slow, see https://github.com/kubernetes/kubernetes/issues/69699
TBH, these K8s 1.20 release notes would be a better link to reference than the github issue, but I’m sure that log item was pre-1.20.
Turns out, by default, fsGroupPolicy is enabled in the NFS CSI helm chart. The affected pods both have a ton of files in their NFS PVC and it was trying to check/change ownership over all of them, taking upwards of 20 mins! Disabled that as part of the Helm chart, and TADA!
After upgrading from my old Synology DS1511+ (yes, 12 years old) to a new Synology DS423+ (highly recommended!) and getting everything migrated, I wanted to wipe the machine to see if I can sell/donate it. It still works great, but I wanted to hard reset it to prepare it for a new owner. Needless to say it didn’t go according to plan, but figured I’d document it here.
As part of the upgrade, I had disconnected the old NAS to ensure there was nothing more I needed on it. It had been sitting in my office for about 3 weeks and I figured it was time to wipe it. I plugged it in, turned it on…and for some reason I couldn’t hit the website. Meh, no matter, I’ll just reset it via the button.
It reset and I was able to find it via find.synology.com and started the reconfigure of it. All worked well until it got to 95%…and sat there. I opened a new browser window and did the same thing…only to have it get stuck at 95% again. Life happened and so I left it there for awhile only to come back to the same issue. Ugh.
So I restarted it…
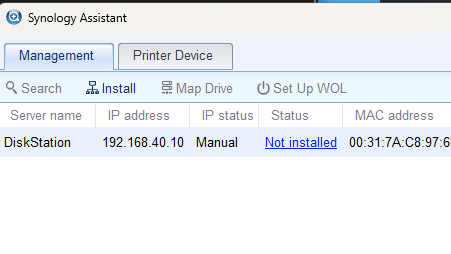
I was still unable to access it via the IP I saw it was getting. I also wasn’t able to find it on find.synology.com. So I attempted to find it via the downloadable Synology Assistant. At first I couldn’t find it there either (Yikes!), but then I realized I was crossing VLANS and the traffic was probably being blocked.
Ok, now I can at least see it, and low and behold DSM isn’t installed on it – so much for “95%”.
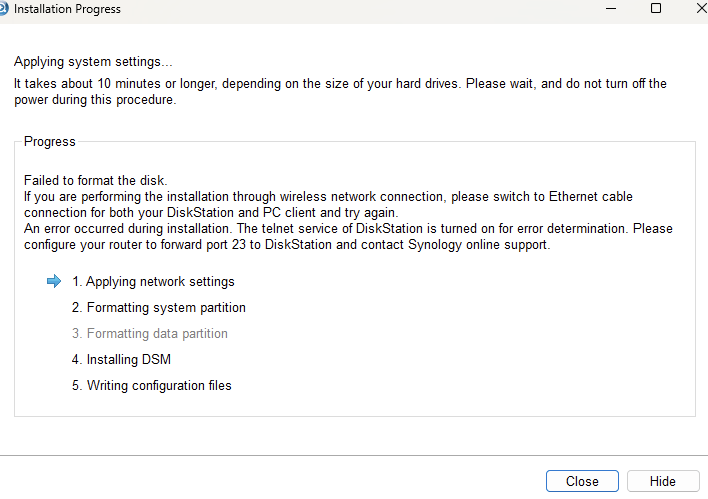
Should be easy at this point, just run the install and tada. Sadly, this is the error I continually received.
As part of the install process it prompts you to input both the networking configuration and the admin password prior to getting to this point. Seeing the error, I then telnet’ed into the machine, but the password I had set it to never worked.
I’m putting the info below, in case that website goes away and is no longer available.
1st character = month in hexadecimal, lower case (1=Jan, … , a=Oct, b=Nov, c=Dec)
2-3 = month in decimal, zero padded and starting in 1 (01, 02, 03, …, 11, 12)
4 = dash
5-6 = day of the month in hex (01, 02 .., 0A, .., 1F)
7-8 = greatest common divisor between month and day, zero padded. This is always a number between 01 and 12.
So, let’s say today is October 15, the password would be: a10-0f05 (a = month in hex, 10 = month in dec, 0f = day in hex, 05 = greatest divisor between 10 and 15).
In some cases the clock is also set to factory default… then try the password: 101-0101
Additionally, by default the TZ is in UTC, so account for that in the day.
The install logs are located at /var/log/messages, and cat’ing that I saw the following:
Feb 4 00:26:38 kernel: [ 3393.572368] ata3: SError: { HostInt 10B8B }
Feb 4 00:26:38 kernel: [ 3393.576648] ata3.00: failed command: READ FPDMA QUEUED
Feb 4 00:26:38 kernel: [ 3393.581931] ata3.00: cmd 60/20:00:00:00:00/00:00:00:00:00/40 tag 0 ncq 16384 in
Feb 4 00:26:38 kernel: [ 3393.581934] res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x44 (timeout)
Feb 4 00:26:38 kernel: [ 3393.597037] ata3.00: status: { DRDY }
Feb 4 00:26:40 kernel: [ 3396.226915] ata3: limiting SATA link speed to 1.5 Gbps
Feb 4 00:26:42 kernel: [ 3398.543647] ata3.00: disabled
Feb 4 00:26:42 kernel: [ 3398.546712] ata3.00: device reported invalid CHS sector 0
Feb 4 00:26:43 kernel: [ 3398.565298] Descriptor sense data with sense descriptors (in hex):
Feb 4 00:26:43 kernel: [ 3398.594016] end_request: I/O error, dev sdc, sector 0
Feb 4 00:26:43 kernel: [ 3398.599194] Buffer I/O error on device sdc, logical block 0
Feb 4 00:26:43 kernel: [ 3398.604882] Buffer I/O error on device sdc, logical block 1
Feb 4 00:26:43 kernel: [ 3398.610580] Buffer I/O error on device sdc, logical block 2
Feb 4 00:26:43 kernel: [ 3398.610705] sd 2:0:0:0: rejecting I/O to offline device
Feb 4 00:26:43 kernel: [ 3398.610792] sd 2:0:0:0: rejecting I/O to offline device
Feb 4 00:26:43 kernel: [ 3398.610815] sd 2:0:0:0: rejecting I/O to offline device
Feb 4 00:26:43 kernel: [ 3398.610858] sd 2:0:0:0: rejecting I/O to offline device
Feb 4 00:26:43 kernel: [ 3398.638050] Buffer I/O error on device sdc, logical block 3
Feb 4 00:26:43 kernel: [ 3398.672656] sd 2:0:0:0: [sdc] START_STOP FAILED
Feb 4 00:26:43 syslog: format start, szBuf = ^R4VxSYNONI^A^D^A
Feb 4 00:26:43 syslog: ninstaller.c:1314 No found '/.raid_assemble', skip it
Feb 4 00:26:43 syslog: ninstaller.c:2235 CleanPartition=[0], CheckBadblocks=[0]
Feb 4 00:26:43 syslog: ninstaller.c:2296(ErrFHOSTDoFdiskFormat) retv=[0]
Feb 4 00:26:43 syslog: ErrFHOSTTcpResponseCmd: cmd=[2], ulErr=[0]
Feb 4 00:26:43 syslog: query prog, szBuf = ^R4VxSYNONI^A^D^A
Feb 4 00:26:43 syslog: ninstaller.c:2150(ErrFHOSTUpdateMkfsProgress) gInstallStage=[3] ret:-34
Feb 4 00:26:43 syslog: index=[0], ulRate=[8]
Feb 4 00:26:43 syslog: ninstaller.c:2221(ErrFHOSTUpdateMkfsProgress) retv=-34
Feb 4 00:26:43 syslog: ninstaller.c:1423(ErrFHOSTNetInstaller) read socket fail, ret=[0], errno=[2]
Feb 4 00:26:43 syslog: ninstaller.c:1512(ErrFHOSTNetInstaller) retSel=[1] err=(2)[No such file or directory]
Feb 4 00:26:43 syslog: ninstaller.c:1527(ErrFHOSTNetInstaller)
Feb 4 00:26:43 syslog: Return from TcpServer()
Feb 4 00:26:43 kernel: [ 3399.370817] md: md1: set sda2 to auto_remap [0]
Feb 4 00:26:43 kernel: [ 3399.401536] md: md0: set sda1 to auto_remap [0]
Feb 4 00:26:43 syslog: raidtool.c:166 Failed to create RAID '/dev/md0' on ''
Feb 4 00:26:43 syslog: raidtool.c:166 Failed to create RAID '/dev/md1' on ''
Feb 4 00:26:43 syslog: ninstaller.c:2249 szCmd=[/etc/installer.sh -n > /dev/null 2>&1], retv=[1]
Feb 4 00:26:43 syslog: ninstaller.c:2293 retv=[1]
Lots more searching of the some of the errors didn’t really get me any real answer, but I was able to find a forum post that seemed relevant that had a link to the web archive of a website that didn’t exist anymore. While that link was about a failed array, looking at my log files it appeared as if the installer couldn’t create the base RAID for a few drives.
While telnet’ed in, a look at my arrays returned with the following:
At this point I tried various things with my drives. I removed them all and tried to run the install again, I tried with a single drive, multiple drives and so on to no avail. I even repartitioned one of the drives on my laptop to be “clean” and tried again. Sadly, none of these worked. Finally, with not much else to try, and after looking at the web archive article how they recreated the array, I decided to try and create it manually via the same tool.
Below is the what I ran and the associated output, which gave me something similar to what is shown in that article for those two arrays.
I then attempted to run the install again, using the same static IP address as I had done before to keep my telnet connection alive, but no love. Quickly looking at the log and seeing similar issues about disk formatting, I figured it hadn’t worked.
Feb 4 00:36:03 kernel: [ 3958.866984] ata1: device unplugged sstatus 0x0
Feb 4 00:36:03 kernel: [ 3958.871556] ata1: exception Emask 0x10 SAct 0x0 SErr 0x4010000 action 0xe frozen
Feb 4 00:36:03 kernel: [ 3958.879115] ata1: irq_stat 0x00400040, connection status changed
Feb 4 00:36:03 kernel: [ 3958.885282] ata1: SError: { PHYRdyChg DevExch }
Feb 4 00:36:06 kernel: [ 3961.934818] ata1: limiting SATA link speed to 1.5 Gbps
Feb 4 00:36:08 kernel: [ 3963.663357] ata1: device plugged sstatus 0x1
Feb 4 00:36:13 kernel: [ 3969.024334] ata1: link is slow to respond, please be patient (ready=0)
Feb 4 00:36:18 kernel: [ 3973.721782] ata1: COMRESET failed (errno=-16)
Feb 4 00:36:20 kernel: [ 3975.681496] ata1.00: revalidation failed (errno=-19)
Feb 4 00:36:20 kernel: [ 3975.686574] ata1.00: disabled
Feb 4 00:37:03 syslog: format start, szBuf = ^R4VxSYNONI^A^D^A
Feb 4 00:37:03 syslog: ninstaller.c:1314 No found '/.raid_assemble', skip it
Feb 4 00:37:03 syslog: ninstaller.c:2235 CleanPartition=[0], CheckBadblocks=[0]
Feb 4 00:37:03 syslog: ninstaller.c:2296(ErrFHOSTDoFdiskFormat) retv=[0]
Feb 4 00:37:03 syslog: ErrFHOSTTcpResponseCmd: cmd=[2], ulErr=[0]
Feb 4 00:37:03 syslog: query prog, szBuf = ^R4VxSYNONI^A^D^A
Feb 4 00:37:03 syslog: ninstaller.c:2150(ErrFHOSTUpdateMkfsProgress) gInstallStage=[3] ret:-34
Feb 4 00:37:03 syslog: index=[0], ulRate=[9]
Feb 4 00:37:03 syslog: ninstaller.c:2221(ErrFHOSTUpdateMkfsProgress) retv=-34
Feb 4 00:37:03 syslog: ninstaller.c:1423(ErrFHOSTNetInstaller) read socket fail, ret=[0], errno=[2]
Feb 4 00:37:03 syslog: ninstaller.c:1512(ErrFHOSTNetInstaller) retSel=[1] err=(2)[No such file or directory]
Feb 4 00:37:03 syslog: ninstaller.c:1527(ErrFHOSTNetInstaller)
Feb 4 00:37:03 syslog: Return from TcpServer()
Feb 4 00:37:05 syslog: ninstaller.c:1199(ErrFHOSTTcpServer) bind port 9998 error (98):Address already in use
Feb 4 00:37:05 syslog: Return from TcpServer()
At this point, I decided as a last ditch effort to open a ticket with Synology. Knowing this thing was so out of support I put a bit of a cry for help at the beginning. But after creating the ticket, I looked more at the log file and realized it wasn’t complaining about the md0 and md1 anymore, and instead focused on the last item…”Address already in use”. Huh, weird.
So I reran the installation again, but picked the next open IP address and not the one that I had used previously…and to my great surprise it actually worked!
After a few reboots, I’m now back into the web UI! There was no volume that was created, but all 5 of my drives are up and running – which is good because I wanted to properly wipe them anyways. Yay!